# JS 重要知识点
# 1、 Javascript 基本数据类型、如何存储的
原始类型包括 6 个: String、Number、Boolean、null、undefined、Symbol
引用类型统称 Object 类型,细分以下 5 个:Object、Array、Date、RegExp、Function
1、数据的存储形式
栈(Stack)和堆(Heap),两种基本的数据结构,栈是在内存中自动分配内存空间的,堆在内存中动态分配内存空间,不一定会释放,一般我们在项目中将对象类型手动置为 null,减少无用内存消耗。
注意: 原始类型按值形式存放栈中,可以直接按值访问
引用类型存放堆中,在栈中保存的是对象在堆中的引用地址
所以会出现下面的情况
var a = 10;
var b = a;
b = 30;
a; // 10
b; // 30
var obj1 = { name: "小明" };
var obj2 = obj1;
obj2.name = "小鹿";
obj1; // {name:'小鹿'}
obj2; // {name:'小鹿'}
2、Null
不同的对象在底层原理的存储是用二进制表示的,在 javaScript 中,如果二进制的前三位都为 0 的话,系统会判定为是 Object 类型。 null 的存储二进制是 000 ,也是前三位,所以系统判定 null 为 Object 类型。
3、数据类型的判断
typeof 与 instanceof 区别?
typeof是一元运算符,返回一个字符串,一般用来判断一个变量是否为空或者什么类型,除了 null 以及 Object 类型不能准确判断外,其他数据类型都可以返回正确类型。可以用 instanceof 来进行判断某个对象是不是另一个对象的实例。返回一个布尔类型。
instanceof 运算符用来测试一对象在其原型链中是否存在一个构造函数的 prototype 属性。
class A {}
console.log(A instanceof Function); // true
# 2、 this 指针,this 指向问题
什么是 this 指针?各种情况下的 this 指向问题?
this 就是一个对象,不同情况下 this 指向不同,以下是几种情况
1、对象调用,this 指向该对象,(谁调用指向谁)
var obj = { name: "小鹿", age: "21", run: function() { console.log(this); console.log(this.name + ":" + this.age); } }; // 通过对象的方式调用函数 obj.run(); // this 指向 obj
- 2、直接调用函数,this 指向的是全局 window 对象。
function print() {
console.log(this);
}
// 全局调用函数
print(); // this 指向 window
- 3、通过 new 的防护,this 永远指向新创建的对象。
function Person(name, age) {
this.name = name;
this.age = age;
console.log(this);
}
var xiaolu = new Person("小鹿", 22); // this => xiaolu
- 4、箭头函数中的 this
由于箭头函数没有单独的 this 值,箭头函数的 this 与声明所在的上下文相同,也就是说调用箭头函数的时候,不会隐式的调用 this 参数,而是从定义时的函数继承上下文
const obj = {
a : ()=>{
console.log(this)
}
}
this => window
改变this指向的三种方式,区别? // call 、 apply 、bind
var obj = {
name: "xiaolu",
age: "22"
};
function print() {
console.log(this);
console.log(arguments);
}
// 通过call改变this指向
print.call(obj, 1, 2, 3);
// 通过apply改变this指向
print.apply(obj, [1, 2, 3]);
// 通过bind改变this指向
let fn = print.bind(obj, 1, 2, 3);
fn();
相同点:都可以改变 this 指向,第一个参数都是 this 指向的对象,后续传参的形式
不同点:call 传参时单个传递的(数组也是可以的),apply 参数必须传数组,否则报错
call、apply 函数的执行是直接执行的,而 bind 函数返回一个函数,调用时执行。
箭头函数没有自己的 this 指针,通过 call、apply 方法调用只能传参,不能绑定 this,第一个参数会忽略
# 3、 创建对象的方式,区别
new 内部发生什么?手写实现一个 new 操作符?
通过 new 创建对象过程包括以下四个阶段:
- 创建一个对象
- 新对象的proto属性指向原函数的 prototype 属性(即继承原函数的原型)
- 将这个新对象绑定到此函数的 this 上。
- 返回新对象。
// new 生成对象过程
function creact(Fn, args) {
let obj = {};
obj.__proto__ = Fn.prototype; // 继承原型上的方法
let res = Fn.apply(obj, args); // 调用函数将属性添加到obj上面
return res instanceof Object ? res : obj; // 返回对象用返回的,否 则用obj
}
// 构造函数
function Test(name, age) {
this.name = name;
this.age = age;
}
Test.prototype.sayName = function() {
console.log(this.name);
};
// 实现new 操作符
const newTest = create(Test, "小鹿", "23");
newTest.sayName(); // 小鹿
字面量、new 构造函数 和 Object.creact() 三种创建对象的不同
- 字面量创建对象代码更少,易读
- 字面量创建对象比 new 一个对象更快,因为 new 时会顺着作用域链向上查找,直到找到 Object()函数为止
- Object.create()方式创建对象,一般用来继承
Object.create(proto, [propertiesObject]);
var People = function (name){ this.name = name; };
People.prototype.sayName = function(){console.log(this.name)};
fucntion Person(name,age){
this.age= age;
People.call(this,name); // 使用call继承People属性
}
// 使用Object.create()方法,实现People原型方法的继承,并修改contructor指向
Person.prototype = Object.create(Prople.prototype,{
constructor:{
configurable:true,
enumerable:true,
value:Person,
writable:true
}
});
var p1 = new Person('person1', 25);
p1.sayName(); //'person1'
# 4、 闭包
什么是作用域?什么是作用域链?
function fn1() {
let a = 1;
}
function fn2() {
let b = 2;
}
声明两个函数,分别创建量两个私有的作用域,一个函数就是一个作用域。每个函数都有一个作用域,查找变量或函数时,由局部作用域到全局作用域依次查找,这些作用域的集合就称为作用域链
什么是闭包?
函数执行,形成一个私有的作用域,保护里面私有变量不受外界干扰,除了保护私有变量外,还可以保护一些内容,这样的模式叫闭包。
闭包的作用有两个,保护和保存。
保护的应用
- 团队开发,每个开发将自己的代码放在一个私有的作用域中,防止相会之间的变量名冲突,通过 return 或 window.xxx 的方式暴露全局下
- jQuery 的源码利用这种保护机制
- 封装私有变量
保存的应用
- 选项卡闭包的解决方案。
事件绑定引发的索引问题,解决,略
# 5、原型和原型链
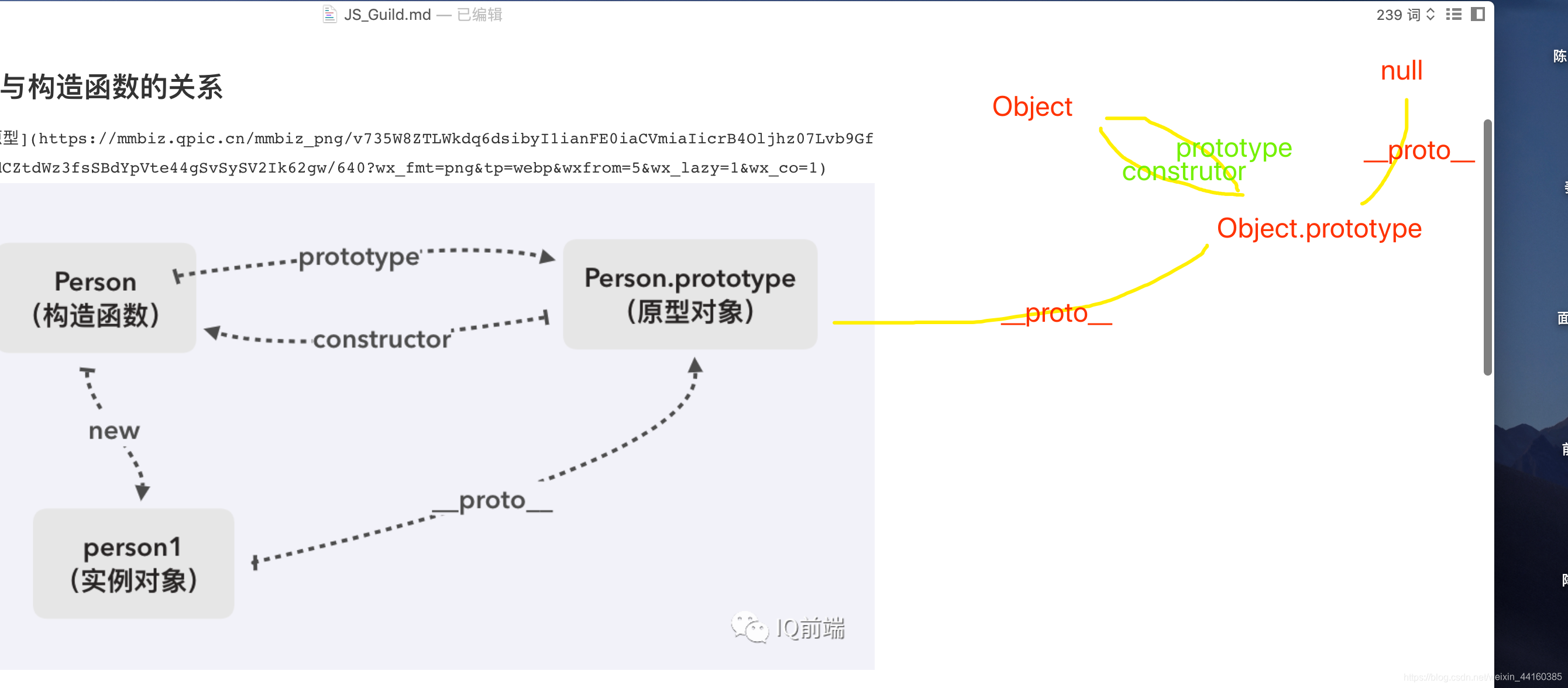
什么是原型?什么是原型链?如何理解?
原型:每个 JS 对象都有一个** proto ** 属性,这个属性指向了原型。
console.log([ ]);
length: 0
** proto ** : Array(0)
只要是对象类型,都会有** proto ** 属性, 这个属性指向也是一个原型对象,原型对象也存在一个 ** proto ** 属性。
原型链:原型链就是多个对象通过** proto **的方式连接起来
原型与构造函数的关系
每个构造函数都有一个原型对象并通过 constructor 指向这个构造函数。
通过构造函数 new 的实例对象有隐式的** proto ** 指向原型对象
原型链与继承
根据上图中思考
当原型对象指向另一个类型的实例对象呢?
会发生以下的事情
 )
)
js 中一切即对象,会通过层层隐式查询,查询到 Object 这个对象的原型上面,并继承上面的属性方法
图中由__proto__属性组成的链子,就是原型链,原型链的终点就是**「null」**。
instanceof 的原理就是通过判断该对象的原型链中是否可以找到该构造类型的 prototype 类型
function Foo(){}
var f1 = new Foo();
console.log(f1 insatnceof Foo); // true
# 6、 JS 中的继承,比较优缺点
继承
继承的方式有哪些?以及各自继承方式的优缺点?
1、经典继承(构造函数)
funciton Father(){
this.colors = ["red","blue","green"];
}
function Son(){
Father.call(this);
}
let s = new Son();
console.log(s.colors) // ["red","blue","green"]
基本思想:在子类的构造函数的内部调用父类的构造函数。
优点:
- 保证了原型链中引用类型的独立,不被所有实例共享。
- 子类创建的时候可以像父类进行传参。
缺点:
- 继承的方法都在构造函数中定义,构造函数不能复用
- 父类定义的方法对于子类型而言是不可见的
2、组合继承
function Father(name) {
this.name = name;
this.colors = ["red", "blue"];
}
// 方法定义在原型对象上(共享)
Father.prototyoe.sayName = function() {
alert(this.name);
};
function Son(name, age) {
// 子类继承父类属性
Father.call(thisc, name);
// this.age = age;
}
// 子类和父类共享的方法(实现了父类属性和方法的复用)
Son.prototype = new Father();
// 子类实例对象共享的方法
Son.prototype.sayAge = function() {
alert(this.age);
};
var instance1 = new Son("louis", 5);
instance1.colors.push("black");
console.log(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //louis
instance1.sayAge(); //5
基本思想
- 使用原型链实现对原型对象属性和方法的继承
- 通过借用构造函数来实现对实例属性的继承
优点
- 每个原型对象上定义的方法实现了函数的复用
- 每个实例都有属于自己的属性
3、原型继承
function object(o) {
function F() {}
F.prototype = o;
// 每次返回的new是不同的
return new F();
}
var person = {
friends: ["Van", "Louis", "Nick"]
};
// 实例 1
var anotherPerson = object(person);
anotherPerson.friends.push("Rob");
// 实例 2
var yetAnotherPerson = object(person);
yetAnotherPerson.friends.push("Style");
// 都添加至原型对象的属性(所共享)
alert(person.friends); // "Van,Louis,Nick,Rob,Style"
基本思想:创建临时构造函数,将传入的对象作为该构造函数的原型对象,返回这个新构造函数的实例
4、寄生式继承
function createAnother(original) {
var clone = object(original); // 通过调用object函数创建一个新对象
clone.sayHi = function() {
alert("hi");
};
return clone; // 返回这个对象
}
- 基本思想:不必为了制定子类型的原型而调用超类型的构造函数
- 优点:寄生组合式继承就是为了解决组合继承中两次构造函数的开销
# 7、 JS 中的垃圾回收机制
什么事内存泄漏?为什么会导致内存泄漏?
: 不再用到的内存,没有及时释放,就叫做内存泄漏
JS 垃圾回收机制
运行原理?
找出不在继续使用的变量,然后释放其内存,按照固定的时间间隔,周期性的执行该垃圾回收操作
两种策略
- 标记清除法
- 引用计数法
如何管理内存
js 内存自动管理的,但是存在一些问题,分配给 web 浏览器的可用内存数量通常比分配给桌面应用程序的少。
为了更好的让页面获得好的性能,必须确保 js 变量占用最少的内存,最好的方式就是不用的变量引用释放掉,叫做解除引用。
- 对于局部变量来说,函数执行完成离开环境变量,变量将自动解除
- 对于全局变量我们需要进行手动解除
var a = 20; // 在对内存中给数值变量分配空间
alert(a + 100); // 使用内存
var a = null; // 使用完毕之后,释放内存空间
通过上边的垃圾回收机制的标记清除法的原理得知,只有与环境变量失去引用的变量才会被标记回收,所以将对象的引用设置为 null,此变量也就失去了引用,等待被垃圾回收器回收。
# 8、 JS 中的深拷贝,浅拷贝
什么是深拷贝?什么是浅拷贝?
因为数据类型分为基本类型和引用类型,对基本类型的拷贝就是对值的复制,但是对于引用类型来说,拷贝的不是值,而是值的地址,最终两个变量的地址指向的是同一个值
var obj1 = { name: "xiaohong" };
var obj2 = obj1;
obj2.name = "limi";
obj1; // {name : 'limi'}
要想将 obj1 和 obj2 的关系断开,也就是让他们不指向同一个地址,根据不同层次的拷贝,分为了深拷贝和浅拷贝
- 浅拷贝: 只进行一层关系的拷贝。
- 深拷贝:进行无线层次的拷贝。
浅拷贝和深拷贝分别如何实现的,有哪几种实现方式?
- 1、浅拷贝
function shallowClone(o) {
const obj = {};
for (let i in o) {
obj[i] = o[i];
}
return obj;
}
- 2、扩展运算符实现
let a = { c: 1 };
let b = { ...a };
a.c = 2;
b.c; // 1
- 3、Object.assign() 实现
let a = { c: 1 };
let b = Object.assign({}, a);
a.c = 2;
b.c; // 1
- 4、深拷贝 ,在浅拷贝的基础上加上递归
var a1 = {b : {c: {d:1 }}}
function deepClone(source) {
var target = {};
for(var i in source) {
if(source.hasOwnProperty(i) {
if(typeof source[i] === 'object'){
target[i] = deepClone(source[i]) // 递归
}else{
target[i] = source[i]
}
})
}
return target;
}
上面深拷贝存在问题
- 参数没有校验
- 判断对象不严谨
- 递归层次深,容易爆栈
- 循环引用问题
var a = {};
a.a = a;
deepClone(a); // 会造成一个死循环
两种解决循环引用问题的方法
- 暴力破解
- 循环检测
- 5、利用 JSON.parse(JSON.stringify(object)) , 但是也有局限
function cloneJSON(source) {
return JSON.parse(JSON.stringify(source));
}
这种方法来说,内部的原理实现也是使用的递归,递归到一定深度,也是会出现爆栈的问题,但是不会造成循环引用的问题,内部解决方案正式用到了循环检测
详细深拷贝实现:------实现中。。
# 9、 js 中的异步编程
由于 Javascript 是单线程的,单线程就是意味着阻塞问题,当一个任务执行完成之后才执行下一个任务,这样会导致出现页面卡死的状态,页面无响应,影响用户体验,所以不得不出现了同步和异步的解决方案。
JS 为什么是单线程?带来了哪些问题呢?
JS 单线程的特点是同一时刻只能执行一个任务,这是由一些与用户的互动以及操作一些 DOM 相关操作决定的。否则使用多线程会带来复杂得瑟同步问题,如果执行同步问题的话,多线程需要加锁,执行任务造成非常的繁琐。
虽然 HTML5 标准规定,允许 JavaScript 脚本创建多个线程,但是子线程完全受主线程控制,且不得操作 DOM。
因为单线程会造成阻塞,为了解决这个问题,不得不涉及 JS 两种任务,分别为同步任务和异步任务
如何实现异步编程?
最早是使用回调函数,在特定的事件或条件发生时调用,如 Ajax 回调
// jQuery 中的ajax
$.ajax({
type:'post',
url:'test.json',
dataType:'json',
success: function(res) {
// 响应成功的回调
},
fail:function(res){
// 响应失败的huidiao
}
})
如果某个请求存在依赖另一个请求,就会形成不断的循环嵌套,我们称之为回调地狱。
异步中 try catch return 问题?
为什么不能捕获异常?
跟 js 的运行机制有关,异步任务执行完成会加入任务队列,当执行栈中没有可执行任务时,主线程才会取出任务队列中的异步任务入栈执行,但是当异步任务执行的时候,捕获异常的函数已经在执行栈中退出了,所以异常无法捕获。
为什么不能 return?
return 只能终止回调的函数执行,而不能终止外部代码的执行
如何解决回调地狱问题呢?
ES6 给我们三种解决方案,分别是 Generator、Promise、async/awiat (ES7)
# 10、 执行上下文
异步代码的执行顺序? Event Loop 的运行机制是如何的运行的?
由上文已知 JS 是单线程并且通过使用同步和异步任务解决 JS 的阻塞问题,那么异步代码执行顺序,以及 EventLoop 是如何运作的呢?
深入事件循环机制,需要弄懂以下概念
- 执行上下文
- 执行栈
- 微任务
- 宏任务
执行上下文
抽象概念:可理解为代码执行的一个环境,
全局执行上下文: 全局 this 指向 window,外部加载的 js 文件或本地< script >标签中的代码
函数执行上下文: 函数调用时创建的新的局部上下文
Eval 执行上下文(不常用)
执行栈
执行栈就是我们数据结构中的"栈",它具有"先进后出"的特点,所以我们代码执行的时候,遇到一个执行上下文就将其依次压入执行栈中。
function foo() {
console.log("a");
bar();
console.log("b");
}
function bar() {
console.log("c");
}
foo();
// a
// c
// b
- 初始化状态,执行栈任务为空
- foo 函数执行,foo 进入执行栈,输出 a,碰到函数 bar
- bar 进入执行栈,开始执行 bar,输出 c
- bar 函数执行完出栈,继续执行执行栈顶端的函数 foo,最后输出 b
- foo 出栈,所有执行栈内任务执行完毕
宏任务
对于宏任务一般包括
script;
setTimeout;
setInterval;
setImmediate;
I / O;
微任务
对于微任务一般包括:
Promise;
Process.nextTick;
MutationObserver;
运行机制
js 事件循环机制,js 中任务执行顺序都是靠函数调用栈来实现的。
- 1、事件循环机制从 script 标签开始,整个 script 标签是作为一个宏任务处理的
- 2、执行过程中,遇到宏任务,如 setTimeout 就将当前任务分发到对应的执行队列中去。
- 3、遇到微任务,如 Promise,在创建实例对象时,代码顺序执行,遇到.then 操作,该任务会分发到微任务队列中去
- 4、script 标签内的代码执行完毕后,同时执行过程中涉及的宏任务和微任务也分配到了相应的队列中去
- 5、此时宏任务执行完毕,再去微任务队列找微任务
- 6、微任务执行完毕,第一轮消息循环执行完毕,页面进行一次渲染
- 7、第二轮消息循环,从宏任务中取出任务队列执行
- 8、如果两个任务队列没有任务可执行了,所有任务执行完毕
演示
<script>
console.log('1');
setTimeout(() => {
console.log('2')
}, 1000);
new Promise((resolve, reject) => {
console.log('3');
resolve();
console.log('4');
}).then(() => {
console.log('5');
});
console.log('6'); // 1、3、4、6、5、2
</script>
简化步骤
- 执行宏任务(script 中同步执行代码), 执行完毕, 调用栈为空
- 检查微任务队列是否有可执行任务,执行完所有微任务
- 进行页面渲染
- 第二轮从宏任务队列去除一个宏任务执行,重复以上循环
← JS 经典面试题 从URL输入到页面展现? →